参考文档: 更多mysql,请参考
数据库介绍
RDBMS 术语
在我们开始学习MySQL 数据库前,让我们先了解下RDBMS的一些术语:
- 数据库: 数据库是一些关联表的集合。.
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同的数据, 例如邮政编码的数据。
- 行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余可以使系统速度更快。(表的规范化程度越高,表与表之间的关系就越多;查询时可能经常需要在多个表之间进行连接查询;而进行连接操作会降低查询速度。例如,学生的信息存储在student表中,院系信息存储在department表中。通过student表中的dept_id字段与department表建立关联关系。如果要查询一个学生所在系的名称,必须从student表中查找学生所在院系的编号(dept_id),然后根据这个编号去department查找系的名称。如果经常需要进行这个操作时,连接查询会浪费很多的时间。因此可以在student表中增加一个冗余字段dept_name,该字段用来存储学生所在院系的名称。这样就不用每次都进行连接操作了。)
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
Mysql数据库
Mysql是最流行的关系型数据库管理系统,在WEB应用方面MySQL是最好的RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。由瑞典MySQL AB公司开发,目前属于Oracle公司。MySQL是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
- Mysql是开源的,所以你不需要支付额外的费用。
- Mysql支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL使用标准的SQL数据语言形式。
- Mysql可以允许于多个系统上,并且支持多种语言。这些编程语言包括C、C++、Python、Java、Perl、PHP、Eiffel、Ruby和Tcl等。
- Mysql对PHP有很好的支持,PHP是目前最流行的Web开发语言。
- MySQL支持大型数据库,支持5000万条记录的数据仓库,32位系统表文件最大可支持4GB,64位系统支持最大的表文件为8TB。
- Mysql是可以定制的,采用了GPL协议,你可以修改源码来开发自己的Mysql系统。
Mysql数据库安装及使用
管理MySQL的命
以下列出了使用Mysql数据库过程中常用的命令:
-
USE 数据库名 :选择要操作的Mysql数据库,使用该命令后所有Mysql命令都只针对该数据库。
-
SHOW DATABASES: 列出 MySQL 数据库管理系统的数据库列表。
-
SHOW TABLES: #显示指定数据库的所有表,使用该命令前需要使用 use命令来选择要操作的数据库。
-
SHOW COLUMNS FROM 数据表: #显示数据表的属性,属性类型,主键信息 ,是否为 NULL,默认值等其他信息。
-
create database testdb charset "utf8"; #创建一个叫testdb的数据库,且让其支持中文
-
drop database testdb; #删除数据库
-
SHOW INDEX FROM 数据表:显示数据表的详细索引信息,包括PRIMARY KEY(主键)。
MySQL 数据类型
MySQL中定义数据字段的类型对你数据库的优化是非常重要的。
MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
数值类型
MySQL支持所有标准SQL数值数据类型。
这些类型包括严格数值数据类型(INTEGER、SMALLINT、DECIMAL和NUMERIC),以及近似数值数据类型(FLOAT、REAL和DOUBLE PRECISION)。
关键字INT是INTEGER的同义词,关键字DEC是DECIMAL的同义词。
BIT数据类型保存位字段值,并且支持MyISAM、MEMORY、InnoDB和BDB表。
作为SQL标准的扩展,MySQL也支持整数类型TINYINT、MEDIUMINT和BIGINT。下面的表显示了需要的每个整数类型的存储和范围。
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 字节 | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 字节 | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 字节 | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 字节 | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 字节 | (-9 233 372 036 854 775 808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 字节 | (-3.402 823 466 E+38,1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度浮点数值 |
| DOUBLE | 8 字节 | (1.797 693 134 862 315 7 E+308,2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
每个时间类型有一个有效值范围和一个"零"值,当指定不合法的MySQL不能表示的值时使用"零"值。
TIMESTAMP类型有专有的自动更新特性,将在后面描述。
| 类型 | 大小(字节) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2037 年某时 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255字节 | 定长字符串 |
| VARCHAR | 0-65535 字节 | 变长字符串 |
| TINYBLOB | 0-255字节 | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255字节 | 短文本字符串 |
| BLOB | 0-65 535字节 | 二进制形式的长文本数据 |
| TEXT | 0-65 535字节 | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215字节 | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295字节 | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295字节 | 极大文本数据 |
CHAR和VARCHAR类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY和VARBINARY类类似于CHAR和VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
BLOB是一个二进制大对象,可以容纳可变数量的数据。有4种BLOB类型:TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB。它们只是可容纳值的最大长度不同。
有4种TEXT类型:TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT。这些对应4种BLOB类型,有相同的最大长度和存储需求。
mysql的常用命令
mysql创建数据表:
用test数据 ,创建一个表叫student,包含stu_id(int类型,不能为空,自动递增) , name(字符类型,不能为空), age(int类型,不能为空), register_date(date格式)
#create table table_name(column_name column_type)use test;#使用test数据库create table student(stu_id int not null auto_increment,name char(32) not null,#字符类型,不能为空age int not null,#int类型,不能为空register_date date,#register_date(date格式)primary key(stu_id))#设置主键为stu_id
插入数据:
语法: insert into table_name(field1,field2,...fieldN) values (value1,value2,...valueN)insert into student(name,age,register_date) values("alex li",22,"2018-04-17") 查询数据语法:
- select column_name,column_name from table_name [where Clause] [offset m][limit n]
- 查询语句中你可以使用一个或者多个表,表之间使用逗号(,)分隔,并使用where语句来设定插叙条件。
- select命令可以读取一条或者多条纪录。
- 你可以使用星号(*)来代替其他字段,select语句会返回表的所有字段数据。
- 你可以通过offset指定select语句开始插叙的数据偏移量。默认情况下偏移量为0.
- 你可以使用limit属性来设定返回的纪录数
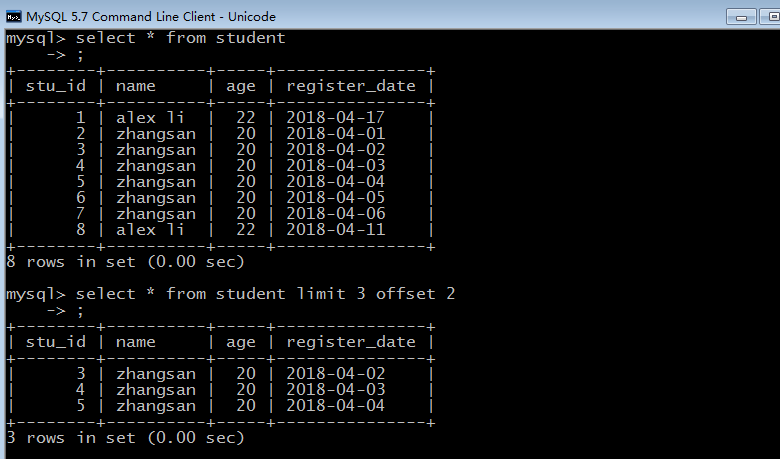
比如这个SQL ,limit后面跟的是3条数据,offset后面是从第3条开始读取
select * from student limit 3 offset 2;
而这个SQL,limit后面是从第3条开始读,读取1条信息。
select * from student limit 3 ,1;
where 子句
语法:select field1,field2,...fieldN from table_name1,table_name2...[where condition1 [and [or]] condition2....]
select * from student where register_date > '2016-03-04'
update 更新语法
UPupdate table_name set fiele1 = new-value1,field2 = new-value2 [where Clause]
upupdate student set age 23 ,name = "Alex Li" where stu_id = 1;
DELETE 语句语法:
delete from table_name [where Clause]
delete from student where stu_id = 5;
MySQL LIKE 子句语法:
select field1,field2,...fieldN table_name1,table_name2... where field1 like condition1 [and[or] filed2 = "somevalue"]
select * from student where name binary like "%Li";select * from student where name binary like binary "%Li";#只匹配大写
MySQL 排序
SELECT field1, field2,...fieldN table_name1, table_name2... ORDER BY field1, [field2...] [ASC [DESC]]
select *from student where name like binary "%Li" order by stu_id desc;
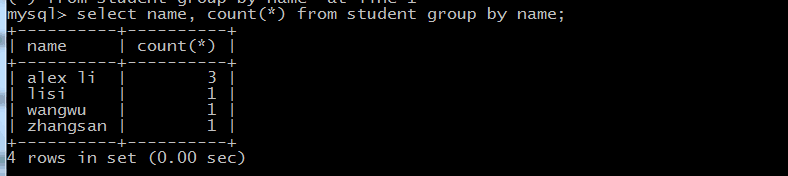
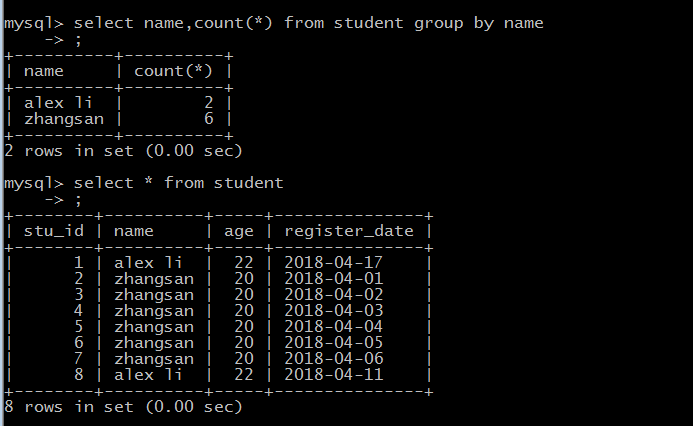
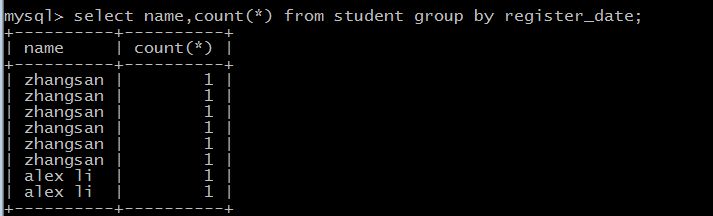
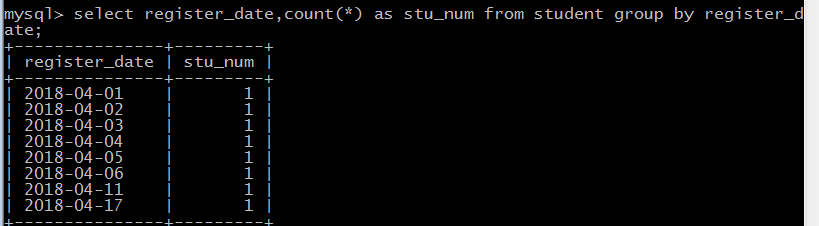
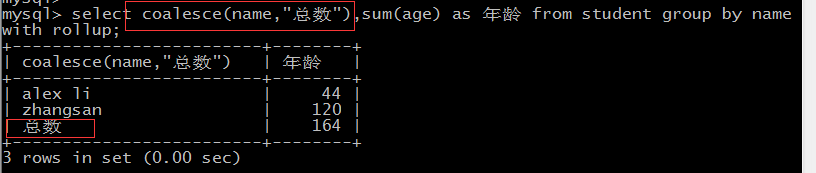
GROUP BY 语句
SELECT column_name, function(column_name)
FROM table_name WHERE column_name operator value GROUP BY column_name; 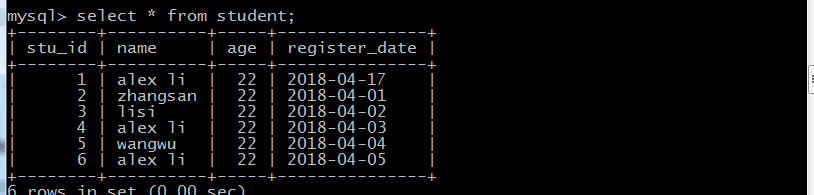

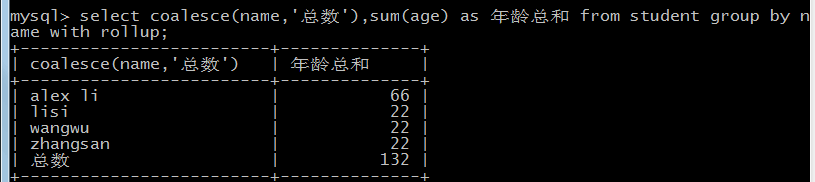
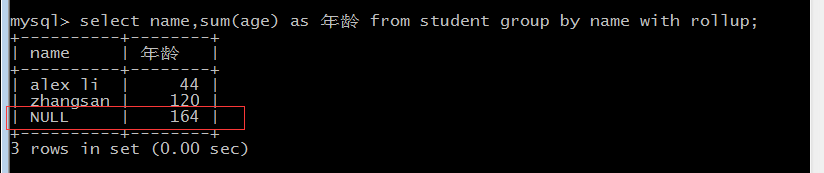
with rollup可以计算总数
coalesce 可以将统计的类别改名,null改为自定义的字符
alter命令
我们需要修改数据表名或者修改数据表字段时,就需要使用到alter命令
增加字段:增加性别字段
alter table student add sex enum("M","F");
删除字段:
alter table student drop age;
修改字段:
利用modify修改sex字段为非空
alter table student modify sex enum("F","M") not null;
利用change修改
alter table student change sex gender char(32) not null default "x";
关于外键
外键,一个特殊的索引,用于关键两个表,只能是指定内容
以下两种写法均可
create table study_record (id int(11) not null auto_increment,day int(11) not null,status char(32) not null ,stu_id int(11) NOT NULL,primary key (id),key fk_student_key (stu_id),constraint fk_student_key foreign key (stu_id) references student (stu_id))CREATE TABLE `study_record` ( `id` int(11) NOT NULL auto_increment, `day` int(11) NOT NULL, `status` char(32) NOT NULL, `stu_id` int(11) NOT NULL, primary key (`id`), key `fk_student_key` (`stu_id`), CONSTRAINT `fk_student_key` FOREIGN KEY (`stu_id`) REFERENCES `student` (`stu_id`))
此时,如果student 对应的stu_id 不存在,study_record也无法插入,这叫外键约束

同样道理,如果有student表中跟这个study_record表有关联的数据,你是不能删除student表中与其关联的纪录
mysql null值处理
我们已经知道MySQL使用 SQL SELECT 命令及 WHERE 子句来读取数据表中的数据,但是当提供的查询条件字段为 NULL 时,该命令可能就无法正常工作。
为了处理这种情况,mysql提供了三大运算符:is null:当列的值是null,此运算符返回True。is not null:当列的值部位null,运算符返回True<=>:比较操作符(不同于=运算符),当比较的两个值都未null时返回True。关于null的条件比较运算是比较特殊的,你不能使用=null或!=null在列中查找null值
在mysql中,null值与任何其他值的比较(即使是null)永远返回false,即null = null返回false。
mysql中处理null使用is null 和is not null运算符。mysql连接(left join,right join,inner join,full join)
这里介绍使用join在两个或多个表中查询数据。
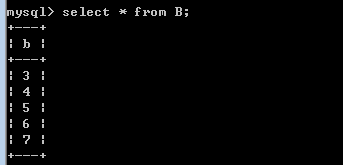
join按照功能大致分为如下三类:inner join(内连接,或等值连接):获取两个表中字段匹配关系的纪录。left join(左连接):获取左表所有纪录,即使右表没有对应匹配的纪录。right join(右连接):与left join相反,用于获取右表所有纪录,即使左表没有对应匹配的纪录。insert into A(a)values(1);
insert into A(a)values(2);insert into A(a)values(3);insert into A(a)values(4);insert into B(b)values(3);
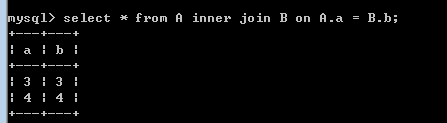
insert into B(b)values(4);insert into B(b)values(5);insert into B(b)values(6);inner join:(显示两个表的交集)
select * from A inner join B on A.a = B.b; #(一般写这个) 可以写成: select A.*,B.* from A,B where A.a = B.b;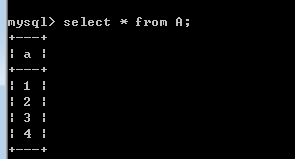
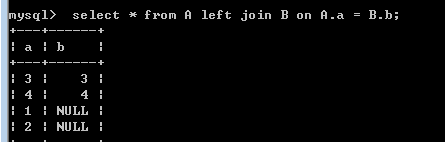
left join:(差集)
select * from A left join B on A.a = B.b;
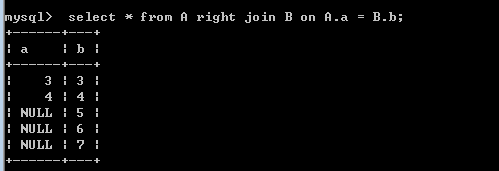
right join:
select * from A right join B on A.a = B.b;
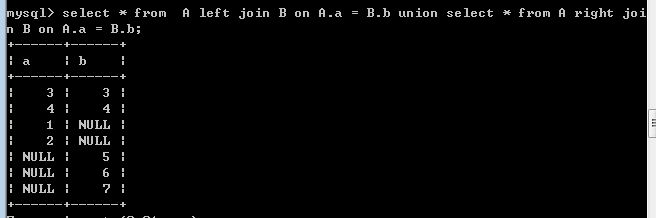
full join:并集(mysql 不直接支持这个)
select * from A full join B on A.a = B.b;#(mysql 不直接支持这个)
mysql支持的写法:
select * from A left join B on A.a = B.b union select * from A right join B on A.a = B.b;
事务
mysql事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,比如信箱、文章等等,这样,这些数据库操作语句就构成了一个事务!
在mysql中只有使用了Innodb数据库引擎的数据库或表才支持事务,mysql默认就使用了这个数据引擎的;事务处理可以用来维护数据库的完整性,包子成批的sql语句要么全部执行,要么全部不执行;事务用来管理insert,update,delete语句;一般来说,事务是必须满足4个条件(ACID):Atomicity(原子性)、Consistency(稳定性)、Isolation(隔离性)、Durability(可靠性)
- 事务的原子性:一组事务,要么成功,要么撤回;
- 稳定性:有非法数据(外键约束之类),事务撤回;
- 隔离性:事务独立运行。一个事务处理后的结果,影响了其他事务,那么其他事务会撤回。事务的100%隔离,需要牺牲速度。
- 可靠性:软、硬件奔溃后,InNoDB数据表驱动会利用日志文件重构修改。可靠性和高速度不可兼得,innodb_flush_log_at_trx_commit选项决定什么时候把事务保存到日志里。
在mysql控制台使用事务来操作
begin;
insert into student (name,age,register_date) values("dashuaige",18,"2018-04-04");rollback;#回滚,这样数据是不会写入的如果是数据没有问题,就输入commit提交命令就行。索引
mysql索引的建立对于mysql的高效运行是很重要的,索引可以大大提高mysql的检索速度。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,单这不是组合索引。组合索引:即一个索包含多个列。(两个合在一起变成唯一的)创建索引时,你需要确保该索引是应用在sql查询语句的条件(一般作为where子句的条件)。
实际上,索引也是一张表,该表保存了主键和索引字段,并指向实体表的纪录。
缺点:索引会降低更新表的速度,如对表进行insert、update、delete,因为更新表时,mysql不仅仅要保存数据,还要保存一下索引文件,所以速度变慢。同时,还要保存一下索引文件,建立索引占用次品空间的索引文件。
普通索引
主键就是默认索引。
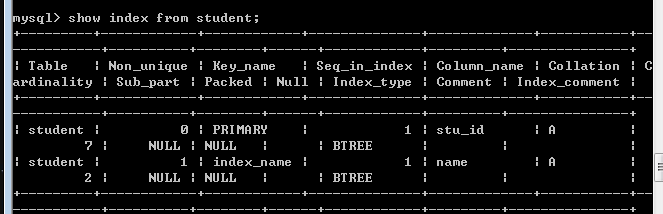
查询索引:show index from student;
创建索引:
语法:create index indexname on mytable (username(length));#length为索引的长度
eg:
create index index_name on student (name(32));
修改表结构
alter mytable add index [indexname] on (username(length))
创建表的时候直接指定
create table mytable(
id int not null,
username varchar(16) not null,
index [indexname] (username(length))
);
删除索引
语法:
drop index [indexname] on mytable;
eg:
drop index index_name on student;
唯一索引
唯一索引:索引列的值必须唯一,但是允许有空值。如果是组合索引,则列值的组合必须唯一。
eg:主键就是唯一索引
创建索引
创建索引
create unique index indexname on mytable(username(length))
修改表结构:
alter mytable add unique [indexname] on (username(length))
创建表的时候直接指定:
create table mytable(\
id int not null,
username varchar(16) not null,
unique [indexname] (username(length))
);
python 操作mysql
参考:点
数据库安装
pip3 install pymysql
使用 pymysql
例子:


import pymysql# 创建连接,相当于建立一个socketconn = pymysql.connect(host = 'localhost',port = 3306,user = 'root',password = 'Choice123',db = 'my_db')# 创建游标,相当于光标,真真正正建立了一个实例cursor = conn.cursor()# 执行SQL,并返回执行行数effect_row = cursor.execute("select * from student")print(effect_row)# 一条条取print(cursor.fetchone())print(cursor.fetchone())print(''.center(60,"="))# 获取前几条数据print(cursor.fetchmany(3))print(''.center(60,"="))# 取全部print(cursor.fetchall()) import pymysql# 创建连接,相当于建立一个socketconn = pymysql.connect(host = 'localhost',port = 3306,user = 'root',password = 'Choice123',db = 'my_db')# 创建游标,相当于光标,真真正正建立了一个实例cursor = conn.cursor()data = [ ("N1","10","2015-05-22"), ("N2", "11", "2015-04-22"), ("N3", "12", "2015-06-22")]cursor.executemany("insert into student (name,age,register_date) VALUES (%s,%s,%s)",data)# 因为默认启动了事务,所以需要commit上去,数据库才有数据conn.commit()# 关闭游标cursor.close()# 关闭连接conn.close()
为了避免写死原生SQL语句,所以介绍ORM
ORM
参考
ORM英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却都是关系型的,为了保证一致的使用习惯,通过ORM将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用功能编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用SQL语言。

ORM的优点:
- 隐藏了数据访问细节,“封闭”的通用数据库交互,ORM的核心。他是的我们的通用数据库交互变得简单,并且完全不用考虑该死的SQL语句。
- ORM使我们构造固话数据结构变得简单易行
缺点:
无可避免的,自动化意味着映射何关联管理,代价是牺牲性能。
sqlalchemy
在python中,最有名的ORM框架是SSQLAlchemy。
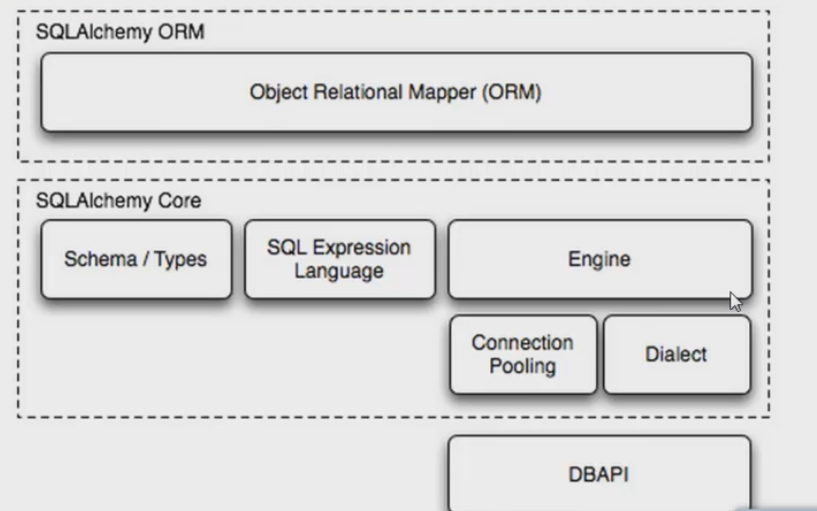
Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Python mysql+mysqldb://: @ [: ]/ pymysql mysql+pymysql:// : @ / [? ] MySQL-Connector mysql+mysqlconnector:// : @ [: ]/ cx_Oracle oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...] 更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html
安装
命令安装:pip3 install sqlalchemy
import sqlalchemyfrom sqlalchemy import create_enginefrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import Column,Integer,String# API接口为mysql与pymysql mysql用户名root 密码Choice123 主机是localhost 数据my_db,类型为utf-8,echo=True,执行这段代码的时候,会打印过程engine = create_engine("mysql+pymysql://root:Choice123@localhost/my_db",encoding = "utf-8",echo = True)# 生成ORM基类Base = declarative_base()class User(Base): # 表名 __tablename__ = 'user' id = Column(Integer,primary_key=True) name = Column(String(32)) password = Column(String(64))# 创建表结构,调用Base类下的metadata方法,调用接口engine,这里是通过父亲调用儿子,生成子类的东西Base.metadata.create_all(engine)
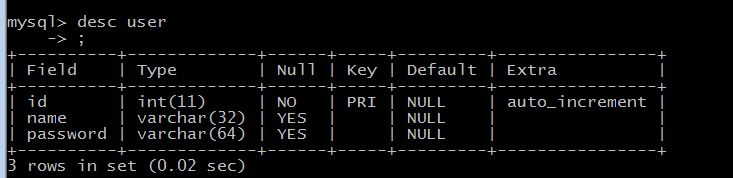
import sqlalchemyfrom sqlalchemy import create_enginefrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import Column,Integer,Stringfrom sqlalchemy.orm import sessionmaker# API接口为mysql与pymysql mysql用户名root 密码Choice123 主机是localhost 数据my_db,类型为utf-8,echo=True,执行这段代码的时候,会打印过程engine = create_engine("mysql+pymysql://root:Choice123@localhost/my_db",encoding = "utf-8",echo = True)# 生成ORM基类Base = declarative_base()class User(Base): # 表名 __tablename__ = 'user' id = Column(Integer,primary_key=True) name = Column(String(32)) password = Column(String(64))# 创建表结构,调用Base类下的metadata方法,调用接口engine,这里是通过父亲调用儿子,生成子类的东西Base.metadata.create_all(engine)# 创建于数据库的会话session class,类似SQL里面的游标,但是这里返回给session的是个类,不是实例,所以下面需要实例化Session_class = sessionmaker(bind=engine)#生成session实例,这里相当于cursorSession = Session_class()# 生成你要创建的数据对象user_obj = User(name= "alex",password = "alex1234")# 此时还没创建对象,只是类里生成了数据,所以数据库的id是没有的print(user_obj.name,user_obj.password)# 把要创建的数据对象添加到session里,一会会统一创建,这里还是没有创建在数据库里面,所以id也是没有的Session.add(user_obj)# 这里统一提交,在数据库创建数据Session.commit()
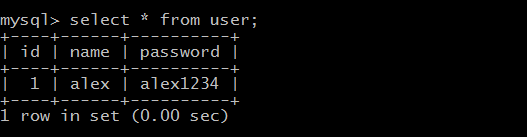
查询 修改 回滚 统计
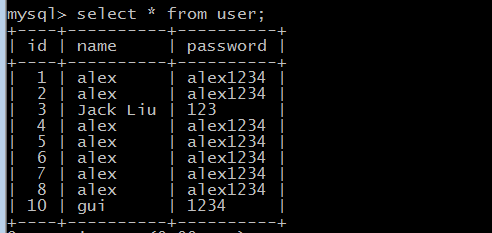
分组统计需要导入:
from sqlalchemy import func
import sqlalchemyfrom sqlalchemy import create_enginefrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import Column,Integer,Stringfrom sqlalchemy.orm import sessionmaker# API接口为mysql与pymysql mysql用户名root 密码Choice123 主机是localhost 数据my_db,类型为utf-8,echo=True,执行这段代码的时候,会打印过程engine = create_engine("mysql+pymysql://root:Choice123@localhost/my_db",encoding = "utf-8")# 生成ORM基类Base = declarative_base()class User(Base): # 表名 __tablename__ = 'user' id = Column(Integer,primary_key=True) name = Column(String(32)) password = Column(String(64)) # 通过这个函数,就能将搜索出来的数据分出来:[<1 name:alex>, <2 name:alex>, <3 name:alex>, <4 name:alex>, <5 name:alex>, <6 name:alex>, <7 name:alex>, <8 name:alex>] def __repr__(self): return "<%s name:%s>" %(self.id,self.name)# 创建表结构,调用Base类下的metadata方法,调用接口engine,这里是通过父亲调用儿子,生成子类的东西Base.metadata.create_all(engine)# 创建于数据库的会话session class,类似SQL里面的游标,但是这里返回给session的是个类,不是实例,所以下面需要实例化Session_class = sessionmaker(bind=engine)#生成session实例,这里相当于cursorSession = Session_class()from sqlalchemy import func# func.count(User.name)是统计name的数量print(Session.query(User.name,func.count(User.name)).group_by(User.name).all())# [('alex', 7), ('gui', 1), ('Jack Liu', 1)] import sqlalchemyfrom sqlalchemy import create_enginefrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import Column,Integer,Stringfrom sqlalchemy.orm import sessionmaker# API接口为mysql与pymysql mysql用户名root 密码Choice123 主机是localhost 数据my_db,类型为utf-8,echo=True,执行这段代码的时候,会打印过程engine = create_engine("mysql+pymysql://root:Choice123@localhost/my_db",encoding = "utf-8")# 生成ORM基类Base = declarative_base()class User(Base):# 表名__tablename__ = 'user'id = Column(Integer,primary_key=True)name = Column(String(32))password = Column(String(64))# 通过这个函数,就能将搜索出来的数据分出来:[<1 name:alex>, <2 name:alex>, <3 name:alex>, <4 name:alex>, <5 name:alex>, <6 name:alex>, <7 name:alex>, <8 name:alex>]def __repr__(self):return "<%s name:%s>" %(self.id,self.name)# 创建表结构,调用Base类下的metadata方法,调用接口engine,这里是通过父亲调用儿子,生成子类的东西Base.metadata.create_all(engine)# 创建于数据库的会话session class,类似SQL里面的游标,但是这里返回给session的是个类,不是实例,所以下面需要实例化Session_class = sessionmaker(bind=engine)#生成session实例,这里相当于cursorSession = Session_class()data = Session.query(User).filter(User.id == 2).one()print("要删除的数据:",data)Session.delete(data)Session.commit()
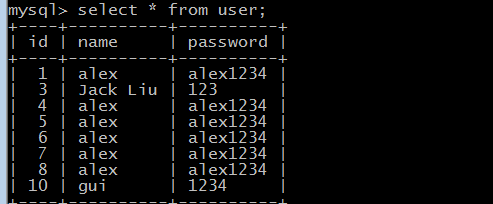
连表
import sqlalchemyfrom sqlalchemy import create_enginefrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import Column,Integer,Stringfrom sqlalchemy.orm import sessionmaker# API接口为mysql与pymysql mysql用户名root 密码Choice123 主机是localhost 数据my_db,类型为utf-8,echo=True,执行这段代码的时候,会打印过程engine = create_engine("mysql+pymysql://root:Choice123@localhost/my_db",encoding = "utf-8")# 生成ORM基类Base = declarative_base()class User(Base):# 表名__tablename__ = 'user'id = Column(Integer,primary_key=True)name = Column(String(32))password = Column(String(64))# 通过这个函数,就能将搜索出来的数据分出来:[<1 name:alex>, <2 name:alex>, <3 name:alex>, <4 name:alex>, <5 name:alex>, <6 name:alex>, <7 name:alex>, <8 name:alex>]def __repr__(self):return "<%s name:%s>" %(self.id,self.name)class Student(Base):__tablename__ = 'student'stu_id = Column(Integer,primary_key=True)name = Column(String(32))age = Column(Integer)# 通过这个函数,就能将搜索出来的数据分出来:[<1 name:alex>, <2 name:alex>, <3 name:alex>, <4 name:alex>, <5 name:alex>, <6 name:alex>, <7 name:alex>, <8 name:alex>]def __repr__(self):return "<%s name:%s>" % (self.stu_id, self.name)# 创建表结构,调用Base类下的metadata方法,调用接口engine,这里是通过父亲调用儿子,生成子类的东西Base.metadata.create_all(engine)# 创建于数据库的会话session class,类似SQL里面的游标,但是这里返回给session的是个类,不是实例,所以下面需要实例化Session_class = sessionmaker(bind=engine)#生成session实例,这里相当于cursorSession = Session_class() print(Session.query(User).filter(User.id == Student.stu_id).all())
关联外键
先删除原来的数据库以免原来的数据影响
drop database my_db;
创建新的数据库,编码为utf8
create database my_db character set utf8;
之后就能执行下面代码
import sqlalchemyfrom sqlalchemy import create_enginefrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import Column,Integer,String,DATE,ForeignKeyfrom sqlalchemy.orm import sessionmaker# API接口为mysql与pymysql mysql用户名root 密码Choice123 主机是localhost 数据my_db,类型为utf-8,echo=True,执行这段代码的时候,会打印过程engine = create_engine("mysql+pymysql://root:Choice123@localhost/my_db",encoding = "utf-8")# 生成ORM基类Base = declarative_base()class Student(Base): __tablename__ = 'student' stu_id = Column(Integer,primary_key=True) name = Column(String(32),nullable=False) age = Column(Integer) register_date = Column(DATE,nullable=False) # 通过这个函数,就能将搜索出来的数据分出来:[<1 name:alex>, <2 name:alex>, <3 name:alex>, <4 name:alex>, <5 name:alex>, <6 name:alex>, <7 name:alex>, <8 name:alex>] def __repr__(self): return "<%s name:%s>" % (self.stu_id, self.name)class StudyRecord(Base): # 表名 __tablename__ = 'study_record' id = Column(Integer, primary_key=True) day = Column(Integer, nullable=False) status = Column(String(32), nullable=False) # 建立外键关系 stu_id = Column(Integer, ForeignKey('student.stu_id')) # 通过这个函数,就能将搜索出来的数据分出来:[<1 name:alex>, <2 name:alex>, <3 name:alex>, <4 name:alex>, <5 name:alex>, <6 name:alex>, <7 name:alex>, <8 name:alex>] def __repr__(self): return "<%s day:%s>" % (self.id, self.day)# 创建表结构,调用Base类下的metadata方法,调用接口engine,这里是通过父亲调用儿子,生成子类的东西Base.metadata.create_all(engine)# 创建于数据库的会话session class,类似SQL里面的游标,但是这里返回给session的是个类,不是实例,所以下面需要实例化Session_class = sessionmaker(bind=engine)#生成session实例,这里相当于cursorSession = Session_class()s1 = Student(name = "Alex",register_date = "2014-05-21")s2 = Student(name = "Jack",register_date = "2014-03-21")s3 = Student(name = "Rain",register_date = "2014-04-21")s4 = Student(name = "Eric",register_date = "2013-01-21")study_r1 = StudyRecord(day = 1,status = "Yes",stu_id = 1)study_r2 = StudyRecord(day = 2,status = "NO",stu_id = 1)study_r3 = StudyRecord(day = 3,status = "Yes",stu_id = 1)study_r4 = StudyRecord(day = 1,status = "Yes",stu_id = 2)# 统一增加Session.add_all([s1,s2,s3,s4,study_r1,study_r2,study_r3,study_r4])# 统一提交Session.commit()
多外键关联
from sqlalchemy import Integer,ForeignKey,String,Columnfrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy.orm import relationshipfrom sqlalchemy import create_engine# API接口为mysql与pymysql mysql用户名root 密码Choice123 主机是localhost 数据my_db,类型为utf-8,echo=True,执行这段代码的时候,会打印过程engine = create_engine("mysql+pymysql://root:Choice123@localhost/my_db",encoding = "utf-8")# 生成ORM基类Base = declarative_base()class Address(Base): __tablename__ = "address" id = Column(Integer,primary_key=True) street = Column(String(64)) city = Column(String(64)) state = Column(String(64)) # 通过这个函数,就能将搜索出来的数据分出来:Alex 转换为:Alex tiantongyuan wudaokou def __repr__(self): return self.streetclass Customer(Base): __tablename__ = "customer" id = Column(Integer,primary_key=True) name = Column(String(64)) # 账单地址以及送货地址都关联了地址 billing_address_id = Column(Integer,ForeignKey("address.id")) shipping_address_id = Column(Integer,ForeignKey("address.id")) # 可以通过billing_address以及shipping_address查询Address类的信息,内容放在内存 billing_address = relationship("Address",foreign_keys = [billing_address_id]) shipping_address = relationship("Address",foreign_keys = [shipping_address_id])# 创建表结构,调用Base类下的metadata方法,调用接口engine,这里是通过父亲调用儿子,生成子类的东西Base.metadata.create_all(engine) import orm_many_fkfrom sqlalchemy.orm import sessionmaker# 创建于数据库的会话session class,类似SQL里面的游标,但是这里返回给session的是个类,不是实例,所以下面需要实例化Session_class = sessionmaker(bind=orm_many_fk.engine)#生成session实例,这里相当于cursorsession = Session_class()# 第一次需要这段代码创建数据# addr1 = orm_many_fk.Address(street = "tiantongyuan",city = "ChangPing",state = "BJ")# addr2 = orm_many_fk.Address(street = "wudaokou",city = "Haidian",state = "BJ")# addr3 = orm_many_fk.Address(street = "Yanjiao",city = "LangFang",state = "HB")## session.add_all([addr1,addr2,addr3])# c1 = orm_many_fk.Customer(name = "Alex",billing_address = addr1,shipping_address = addr2)# c2 = orm_many_fk.Customer(name = "Jack",billing_address = addr3,shipping_address = addr3)## session.add_all([c1,c2])# session.commit()obj = session.query(orm_many_fk.Customer).filter(orm_many_fk.Customer.name == "alex").first()print(obj.name,obj.billing_address,obj.shipping_address)
多对多关联
#一本书可以有多个作者,一个作者又可以出版多本书from sqlalchemy import Table, Column, Integer,String,DATE, ForeignKeyfrom sqlalchemy.orm import relationshipfrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import create_enginefrom sqlalchemy.orm import sessionmakerBase = declarative_base()# 第三张表用这个创建,因为这个表不需要用ORM更新book_m2m_author = Table('book_m2m_author', Base.metadata,Column('book_id',Integer,ForeignKey('books.id')),Column('author_id',Integer,ForeignKey('authors.id')),)# 这种方式创建class Book(Base):__tablename__ = 'books'id = Column(Integer,primary_key=True)name = Column(String(64))pub_date = Column(DATE)## authors关联第三张表,不是真实的字段,通过secondary查询第三张表数据,Author通过backrep决定books反过来查询这张表Bookauthors = relationship('Author',secondary=book_m2m_author,backref='books')def __repr__(self):return self.nameclass Author(Base):__tablename__ = 'authors'id = Column(Integer, primary_key=True)name = Column(String(32))def __repr__(self):return self.name# API接口为mysql与pymysql mysql用户名root 密码Choice123 主机是localhost 数据my_db,类型为utf-8,echo=True,执行这段代码的时候,会打印过程engine = create_engine("mysql+pymysql://root:Choice123@localhost/my_db",encoding = "utf-8")# 创建表结构,调用Base类下的metadata方法,调用接口engine,这里是通过父亲调用儿子,生成子类的东西Base.metadata.create_all(engine) import orm_m2mfrom sqlalchemy.orm import sessionmaker# 创建于数据库的会话session class,类似SQL里面的游标,但是这里返回给session的是个类,不是实例,所以下面需要实例化Session_class = sessionmaker(bind=orm_m2m.engine)#生成session实例,这里相当于cursorsession = Session_class()# 第一次需要这段代码创建数据b1 = orm_m2m.Book(name = "learn python with Alex",pub_date = "2015-05-05")b2 = orm_m2m.Book(name = "learn Zhangbility with Alex",pub_date = "2015-09-05")b3 = orm_m2m.Book(name = "learn hook up girls with Alex",pub_date = "2014-10-05")a1 = orm_m2m.Author(name = "Alex")a2 = orm_m2m.Author(name = "Jack")a3 = orm_m2m.Author(name = "Rain")# 建立第三张表的关联关系b1.authors = [a1,a3]b3.authors = [a1,a2,a3]session.add_all([b1,b2,b3,a1,a2,a3])session.commit() # obj = session.query(orm_m2m.Customer).filter(orm_m2m.Customer.name == "alex").first()# print(obj.name,obj.billing_address,obj.shipping_address)
orm_m2m_api查询
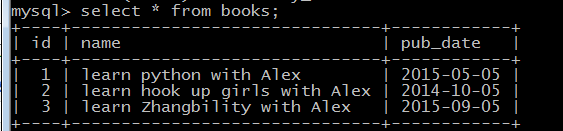
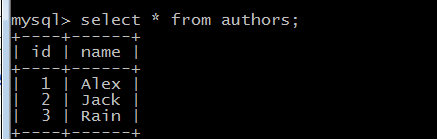
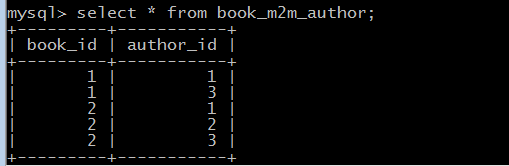
多对多删除
删除数据时不用管boo_m2m_authors , sqlalchemy会自动帮你把对应的数据删除
author_obj =s.query(Author).filter_by(name="Jack").first()book_obj = s.query(Book).filter_by(name="跟Alex学把妹").first()book_obj.authors.remove(author_obj) #从一本书里删除一个作者s.commit()
import orm_m2mfrom sqlalchemy.orm import sessionmaker# 创建于数据库的会话session class,类似SQL里面的游标,但是这里返回给session的是个类,不是实例,所以下面需要实例化Session_class = sessionmaker(bind=orm_m2m.engine)#生成session实例,这里相当于cursorsession = Session_class()# author_obj = session.query(orm_m2m.Author).filter(orm_m2m.Author.name == "alex").first()# print(author_obj.name,author_obj.books)## book_obj = session.query(orm_m2m.Book).filter(orm_m2m.Book.id == 2).first()# book_obj.authors.remove(author_obj)## session.commit()author_obj = session.query(orm_m2m.Author).filter(orm_m2m.Author.name == "alex").first()print(author_obj.name,author_obj.books)session.delete(author_obj)session.commit()
若需要写入中文,需要将引擎这样写:
# API接口为mysql与pymysql mysql用户名root 密码Choice123 主机是localhost 数据my_db,类型为utf-8,echo=True,执行这段代码的时候,会打印过程 engine = create_engine("mysql+pymysql://root:Choice123@localhost/my_db?charset=utf8",encoding = "utf-8") #一本书可以有多个作者,一个作者又可以出版多本书from sqlalchemy import Table, Column, Integer,String,DATE, ForeignKeyfrom sqlalchemy.orm import relationshipfrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import create_enginefrom sqlalchemy.orm import sessionmakerBase = declarative_base()# 第三张表用这个创建,因为这个表不需要用ORM更新book_m2m_author = Table('book_m2m_author', Base.metadata, Column('book_id',Integer,ForeignKey('books.id')), Column('author_id',Integer,ForeignKey('authors.id')), )# 这种方式创建class Book(Base): __tablename__ = 'books' id = Column(Integer,primary_key=True) name = Column(String(64)) pub_date = Column(DATE) # # authors关联第三张表,不是真实的字段,通过secondary查询第三张表数据,Author通过backrep决定books反过来查询这张表Book authors = relationship('Author',secondary=book_m2m_author,backref='books') def __repr__(self): return self.nameclass Author(Base): __tablename__ = 'authors' id = Column(Integer, primary_key=True) name = Column(String(32)) def __repr__(self): return self.name# API接口为mysql与pymysql mysql用户名root 密码Choice123 主机是localhost 数据my_db,类型为utf-8,echo=True,执行这段代码的时候,会打印过程engine = create_engine("mysql+pymysql://root:Choice123@localhost/my_db?charset=utf8",encoding = "utf-8")# 创建表结构,调用Base类下的metadata方法,调用接口engine,这里是通过父亲调用儿子,生成子类的东西Base.metadata.create_all(engine) import orm_m2mfrom sqlalchemy.orm import sessionmaker# 创建于数据库的会话session class,类似SQL里面的游标,但是这里返回给session的是个类,不是实例,所以下面需要实例化Session_class = sessionmaker(bind=orm_m2m.engine)#生成session实例,这里相当于cursorsession = Session_class()# b1 = orm_m2m.Book(name = "learn python with Alex",pub_date = "2015-05-05")b1 = orm_m2m.Book(name = "中文书本名称",pub_date = "2018-05-05")session.add(b1)session.commit()